



Industrielle Datenkontextualisierung: Warum rohe OT-Daten scheitern
Die nächste Wettbewerbsgrenze in der industriellen Fertigung liegt nicht im Sammeln von mehr Daten — sondern darin, ihnen am Punkt der Erfassung Bedeutung zu geben.
In der globalen Debatte rund um OT-Integrationen — DCS, PLC, SCADA-Systeme — und das breitere Industrial Internet of Things (IIoT) haben wir mehr als ein Jahrzehnt damit verbracht, uns auf den Akt der Konnektivität zu konzentrieren. Wir haben den technischen Meilenstein gefeiert, ein Signal von einem Sensor abzugreifen und es in einer Cloud-Datenbank abzulegen. Das war notwendig. Aber es war nie ausreichend.
Im Jahr 2026 hat die Industrie eine kritische Plateauphase erreicht. Die Herausforderung moderner Fertigung ist nicht mehr die Knappheit von Daten — es ist der Semantic Gap: die tiefe Kluft zwischen einem technischen Prozesswert und seiner operativen Bedeutung. Viele Unternehmen — insbesondere jene, die das Problem aus einer Cloud-first-Perspektive angehen — sind datensatt, aber entscheidungsarm. Diesen Gap zu schließen ist der einzige Weg von reaktivem Monitoring zu echter Decision Intelligence. Für Teams, die bereits direkt an den datenproduzierenden Schnittstellen arbeiten — am PLC, am DCS, am Historian — sieht dieser Gap anders aus, aber er verschwindet nicht.
Warum OT-Daten ohne Kontext wertlos sind: Der Semantic Gap in der Fertigung
In High-Tech-Produktionsumgebungen erzeugen Feldebene und Shopfloor jede Sekunde Millionen technischer Rohdatenpunkte. Und doch zeigt sich branchenweit ein konsistentes Muster: Unternehmen haben ihre Datenerfassungskapazitäten in den letzten Jahren dramatisch ausgebaut — während der Anteil dieser Daten, der tatsächlich für Entscheidungen genutzt wird, hartnäckig gering bleibt. Der Schuldige ist nicht fehlender Speicher. Es ist fehlende Struktur.
Technische Rohdaten, die ihres Prozesskontexts beraubt sind, sind von Natur aus stumm.
„Ein Temperaturwert von 85 °C, isoliert in einem PLC-Register, ist ein bedeutungsloses Fragment. Er reift erst dann zu Decision Intelligence heran, wenn er semantisch einem konkreten Asset, einer laufenden Prozessphase und einem eindeutigen Produktionsbatch zugeordnet wird."
Ohne diese logische Verknüpfung bauen wir kein Fundament für KI oder Analytics. Wir schaffen Data Swamps — teure digitale Friedhöfe, auf denen Informationen abgelegt, aber nie abgerufen werden. Bei cts ist unsere Haltung klar: Damit Daten entscheidungsbereit sind, müssen sie unter einer einheitlichen Architekturlogik erfasst und integriert werden, die die Lücke zwischen Shopfloor und Führungsetage überbrückt.
Industrial Data Fabric vs. Data Lake: Warum Fertigung mehr als Speicher braucht
Um diese Fragmentierung zu adressieren, haben wir ein strategisches Framework verfeinert, das auf dem Industrial Data Fabric (IDF) aufbaut — primär mit AspenTech Inmation als Orchestrierungsschicht. Anders als klassische Data Lakes, Data Warehouses oder andere Punkt-zu-Punkt-Integrationsansätze, denen oft Governance fehlt, agiert ein IDF als horizontale, herstellerunabhängige Plattform, die einen Digital Twin der Daten selbst erzeugt.
Laut Gartner gehören Data-Fabric-Architekturen zu den strategischen Top-Prioritäten, weil sie den Aufwand für Datenmanagement um bis zu 70 % reduzieren können — durch Automatisierung der Integration heterogener Quellen. Wenn verschiedene Plattformen und Ansätze für die Umsetzung eines Data Fabric existieren, wird eine Frage sehr praktisch: Warum den schweren Weg gehen, wenn es einen einfachen gibt? Genau das ist der Fall bei AspenTech Inmation — eine Architektur, die den Bedarf an fragilen Custom-Integrationen beseitigt, ohne Governance oder Skalierbarkeit zu opfern.
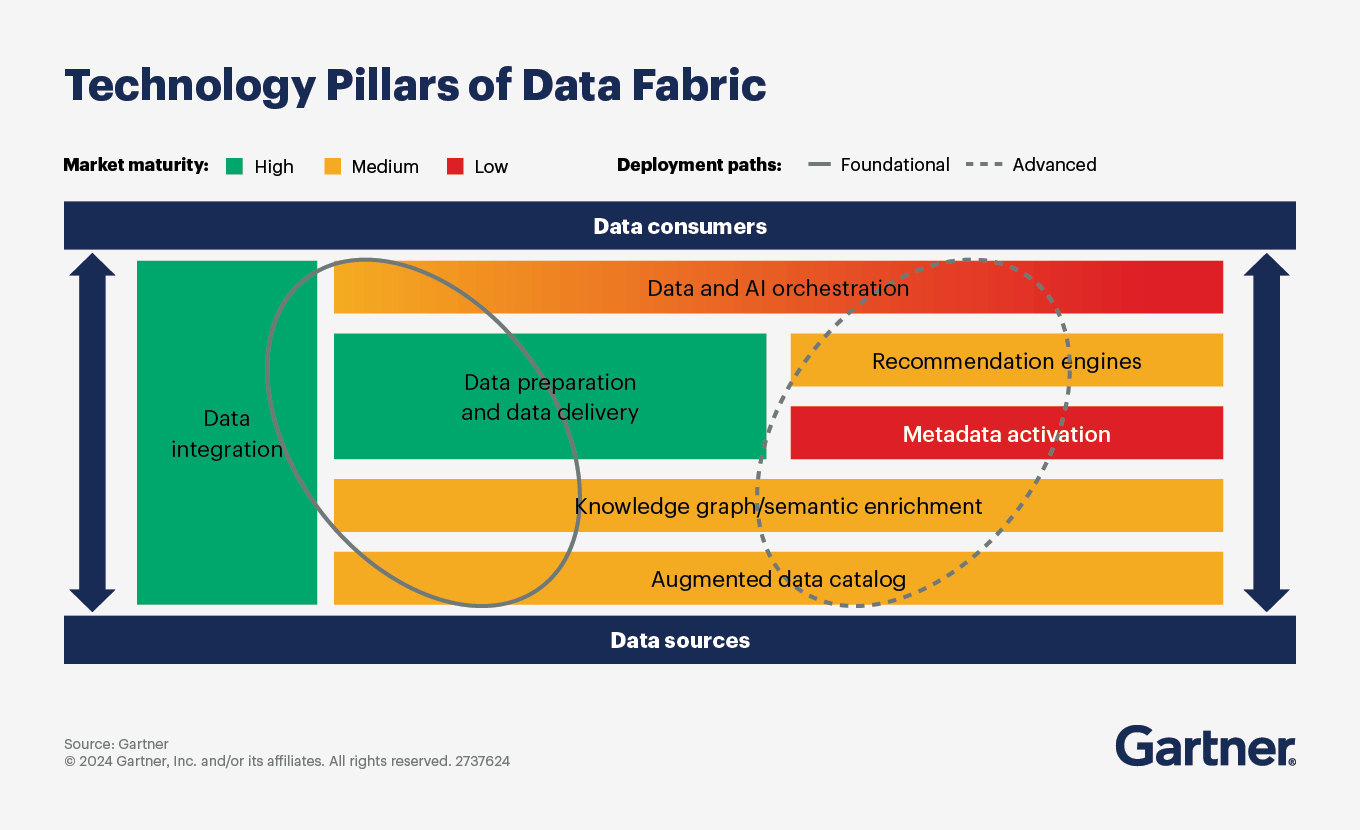
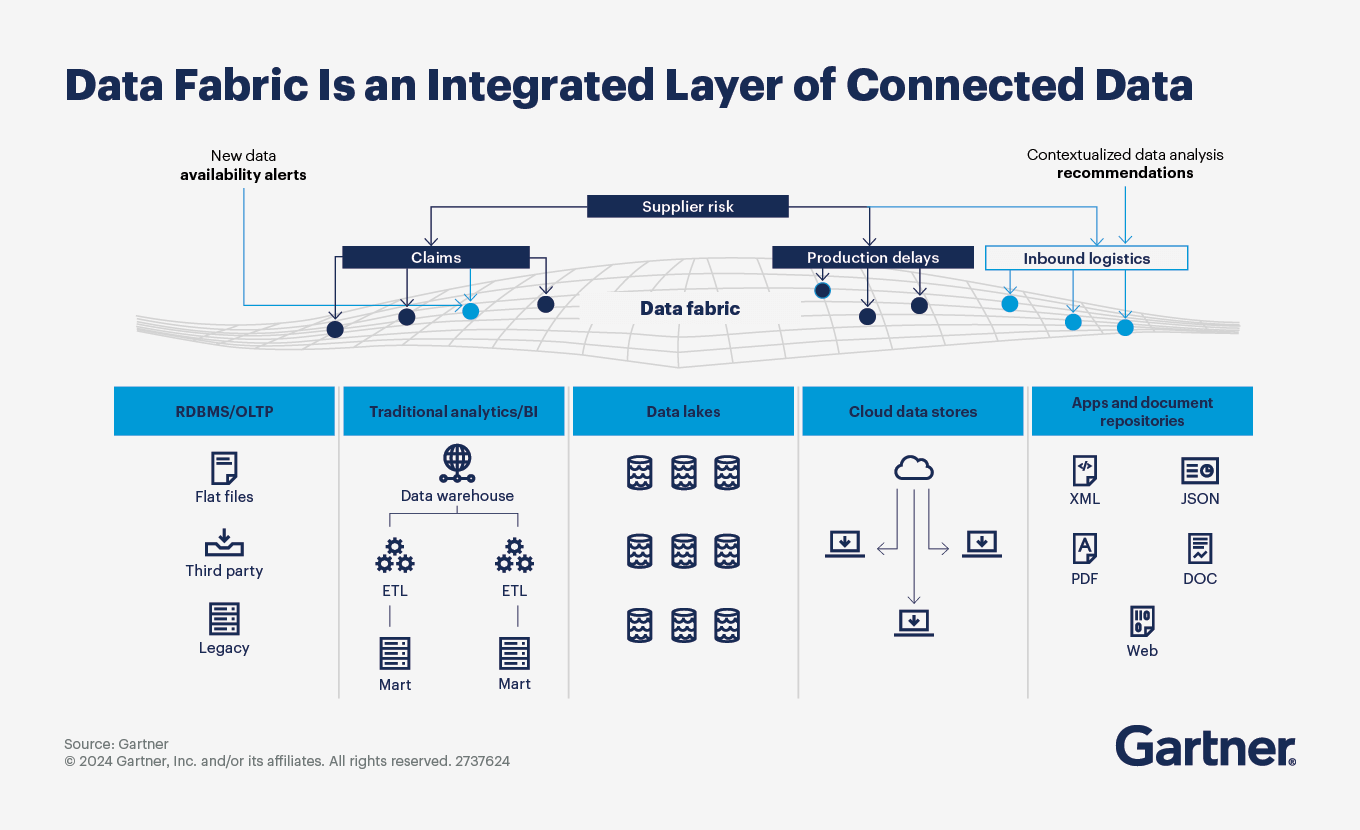
Unser Ansatz bei cts zielt darauf ab, Datensilos aufzulösen, indem wir eine durchgehende Verbindung vom Sensor bis zur ERP-Ebene schaffen. Durch die Normalisierung heterogener Daten aus spezialisierten Systemen — wie AVEVA PI, AspenTech IP.21 oder laborspezifischen Plattformen wie Mettler Toledo LabX — stellen wir eine einzige, verlässliche Faktenbasis bereit. Das ist nicht nur eine technische Integration. Es ist eine strukturelle Transformation, die etwas ermöglicht, das oft übersehen wird: Datenaustausch und Informationsfluss im selben Ökosystem — einschließlich der Kommunikation mit und von Leitsystemen wie DCS und PLC — der auf anderem Weg unmöglich oder prohibitiv aufwendig wäre.
Wenn Daten bereits beim Eingang kontextualisiert werden, sinkt der Aufwand für Compliance und Audit-Trailing erheblich. Das System liefert einen nahtlosen, manipulationssicheren Datensatz by Design — eine einzige Quelle des Wissens, nicht nur eine einzige Quelle der Ablage.
Von reaktivem Monitoring zu Industrial Analytics: Die Daten-Reifegradkurve
Das übergeordnete Ziel dieses Architekturwandels ist es, das Unternehmen auf der Reifegradkurve nach oben zu bewegen. Bei cts nutzen wir moderne Werkzeuge wie Power BI und Industrial Analytics nicht nur, um zu sehen, was gestern passiert ist — sondern um zu verstehen, was gerade jetzt geschieht und was morgen wahrscheinlich eintreten wird.
Das erfordert, den Industrial Data Fabric als sichere, skalierbare Lösung zu behandeln, die gegen externe Bedrohungen schützt und gleichzeitig offen genug bleibt, um globale Rollouts zu unterstützen. Branchenforschung zeigt konsistent: Fertigungsunternehmen, die Datenkontextualisierung beherrschen, erzielen messbare Reduktionen bei qualitätsbezogenen Kosten und einen signifikanten Anstieg der OEE (Overall Equipment Effectiveness). Die Organisationen, die diese Ergebnisse erreichen, tun es nicht durch bessere Software-Lizenzen — sondern durch bessere Datenstrukturen.
Bei cts schöpfen wir aus unserer Hands-on-Praxis, um sicherzustellen, dass diese digitale Transformation kein reines IT-Projekt ist. Sie ist eine operative Realität, die die Gegebenheiten und Feinheiten des Shopfloors versteht.
Was Industrieführer über datengetriebene Fertigung wissen müssen
Der Übergang zum datengetriebenen Unternehmen ist mehr als eine technische Herausforderung — er erfordert organisatorische Ausrichtung, Management-Commitment und eine klare strategische Sprache, die Entscheidungsträger anspricht, nicht nur Automatisierungsspezialisten. Context is King ist der Auftakt einer Reihe, die verschiedene Dimensionen dieser Transformation beleuchtet. Folgebeiträge werden Architekturentscheidungen, Change Management und die Organisationsstrukturen adressieren, die diese Plattformen skalierbar machen.
Der Wettbewerbsvorteil der kommenden Jahre wird nicht dem Unternehmen mit den meisten Sensoren gehören. Er wird demjenigen gehören, das diese Signale in eine transparente, echtzeitfähige Erzählung seiner Produktion übersetzen kann — zugänglich und handlungsrelevant auf jeder Ebene der Organisation. Kontext ist nicht nur ein technisches Feature. Er ist der König der modernen Industriewirtschaft.
Bereit, Ihren Semantic Gap zu schließen?
Sprechen Sie mit unserem Industrial-Informatics-Team bei der cts Group — wir begleiten Sie vom Sensor bis in die Führungsetage.

